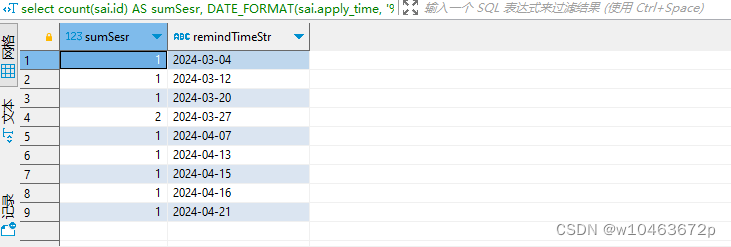
Hello World 实例 数字求和 平方根 二次方程 计算三角形的面积 计算圆的面积 随机数生成 摄氏温度转华氏温度 交换变量 if 语句 判断字符串是否为数字 判断奇数偶数 判断闰年 获取最大值函数 质数判断 输出指定范围内的素数 阶乘实例 九九乘法表 斐波那契数列 阿姆斯特朗数 十进制转二进制、八进制、十六进制 ASCII码与字符相互转换 最大公约数算法 最小公倍数算法 简单计算器实现 生成日历 使用递归斐波那契数列 文件 IO 字符串判断 字符串大小写转换 计算每个月天数 获取昨天日期 list 常用操作 约瑟夫生者死者小游戏 五人分鱼 实现秒表功能 计算 n 个自然数的立方和 计算数组元素之和 数组翻转指定个数的元素 将列表中的头尾两个元素对调 将列表中的指定位置的两个元素对调 翻转列表 判断元素是否在列表中存在 清空列表 移除列表中重复的元素 复制列表 计算元素在列表中出现的次数 计算列表元素之和 计算列表元素之积 查找列表中最小元素 查找列表中最大元素 移除字符串中的指定位置字符 判断字符串是否存在子字符串 判断字符串长度 使用正则表达式提取字符串中的 URL 将字符串作为代码执行 字符串翻转 对字符串切片及翻转 按键(key)或值(value)对字典进行排序 计算字典值之和 移除字典点键值(key/value)对 合并字典 将字符串的时间转换为时间戳 获取几天前的时间 将时间戳转换为指定格式日期 打印自己设计的字体 二分查找 线性查找 插入排序 快速排序 选择排序 冒泡排序 归并排序 堆排序 计数排序 希尔排序 拓扑排序
"""
正则表达式:
正则表达式(Regular Expression,简称 regex)是一种用于模式匹配和文本处理的强大工具,它定义了一种字符串匹配的模式,能够快速有效地搜索、替换、提取或验证文本中的特定字符串或字符序列。以下是正则表达式的主要规则和组成部分:
基本规则和概念:
字符匹配:
普通字符:大多数字母、数字、标点符号等直接匹配自身。
特殊字符(元字符):具有特殊意义的字符,如 ., ^, $, *, +, ?, {}, (, ), [, ], \ 等,它们不直接匹配自身,而是用于构建更复杂的模式。
量词:
?:前一个元素可选,出现0次或1次。
*:前一个元素出现0次或任意多次。
+:前一个元素出现至少1次,最多无限次。
{n}:前一个元素精确出现n次。
{n,}:前一个元素至少出现n次。
{n,m}:前一个元素至少出现n次,至多出现m次。
位置匹配:
^:匹配字符串的开始位置。
$:匹配字符串的结束位置。
\b:匹配单词边界(空格、标点符号与字母数字之间的位置)。
\B:匹配非单词边界。
字符类:
[abc]:匹配括号内任何一个字符,如a、b或c。
[^abc]:否定字符类,匹配任何不在括号内的字符。
[a-zA-Z]:范围表示,匹配指定范围内任意字符。
\d:等价于 [0-9],匹配任意数字。
\D:等价于 [^0-9],匹配任意非数字字符。
\w:等价于 [a-zA-Z0-9_],匹配字母、数字或下划线。
\W:等价于 [^a-zA-Z0-9_],匹配非字母、数字或下划线的字符。
\s:匹配任意空白字符,包括空格、制表符、换页符等。
\S:匹配任意非空白字符。
预定义字符类(POSIX 字符类):
[:alnum:]:字母和数字。
[:alpha:]:字母。
[:digit:]:数字(等同于\d)。
[:lower:]:小写字母。
[:upper:]:大写字母。
[:space:]:空白字符(等同于\s)。
[:punct:]:标点符号。
[:xdigit:]:十六进制数字(0-9、A-F、a-f)。
转义字符:
\(反斜杠)用于转义特殊字符,使其失去特殊意义,如 \\ 匹配反斜杠本身,\. 匹配句点。
分组与捕获:
(pattern):将 pattern 分为一个子表达式或捕获组,可以用于重复、后向引用、条件匹配等。
(?P<name>pattern):命名捕获组,为捕获组赋予名称,便于后续引用。
非捕获组:
(?:pattern):不捕获匹配结果,只用于分组逻辑,不影响捕获组编号。
后向引用:
\number 或 (?P=name):引用先前定义的捕获组内容,number 是捕获组编号,name 是命名捕获组的名称。
零宽断言(Lookaround):
(?=pattern):正向先行断言,要求pattern出现在当前位置之后,但不计入匹配结果。
(?!pattern):负向先行断言,要求pattern不出现于当前位置之后。
(?<=pattern):正向后发断言,要求pattern出现在当前位置之前,但不计入匹配结果。
(?<!pattern):负向后发断言,要求pattern不出现于当前位置之前。
选择(|)、连字符(-)与区间:
A|B:匹配 A 或 B。
[a-z]:在字符类中,- 表示一个连续的字符区间,如 [a-z] 匹配任何小写字母。
其他高级特性(取决于具体实现):
条件匹配(如 (?:(?(id/name)yes-pattern|no-pattern))):根据先前捕获组是否匹配执行不同的模式。
嵌套捕获组:在一个捕获组内部可以定义另一个捕获组。
原子组(如 (?>(pattern))):防止回溯影响到组内的匹配。
注释(如 (?#comment)):在正则表达式中添加注释。
使用正则表达式的常见操作:
匹配验证:检查字符串是否符合某个模式。
搜索:在文本中查找符合模式的所有子串。
替换:将符合模式的子串替换为另一字符串。
提取:从文本中提取符合模式的部分,通常与捕获组配合使用。
注意事项:
正则表达式的行为可能因不同的编程语言或库而有所不同,应参考相关文档了解具体实现细节。
正则表达式引擎通常支持多种匹配模式,如贪婪匹配(默认)、懒惰匹配(使用量词后加 ?,如 *?, +?, {n,m}?)等。
掌握这些规则后,您可以构造出复杂而精确的模式,用于处理各种文本数据问题。
"""
import calendar
import cmath
import datetime
import math
import random
import re
import time
from collections import deque
from functools import reduce
class Example :
def hello_wolrd ( self) :
"""
# >>> print("hello world!")
hello world!
"""
return 'hello world!'
def sum_num ( self, * keys) :
"""
求和
# >>> print(sum(keys))
"""
return sum ( keys)
def square_root ( self, num) :
"""
平方根
# >>> print(math.sqrt(num))
"""
return math. sqrt( num)
def quadratic_equation ( self, equation) :
"""
求二次方程
# >>> print(x.quadratic_equation())
"""
y = equation. split( ' ' )
a, b, c = y[ 0 ] , y[ 2 ] , y[ 4 ]
a = float ( 1 if a. split( 'x^2' ) [ 0 ] == '' else a. split( 'x^2' ) [ 0 ] )
b = float ( 1 if b. split( 'x' ) [ 0 ] == '' else b. split( 'x' ) [ 0 ] )
c = float ( c. split( '=' ) [ 0 ] )
x1 = ( - b + cmath. sqrt( b ** 2 - 4 * a * c) ) / ( 2 * a)
x2 = ( - b - cmath. sqrt( b ** 2 - 4 * a * c) ) / ( 2 * a)
print ( "结果 {0},和 {1}" . format ( x1, x2) )
def triangle_area ( self, a, h) :
"""
求三角形面积
a : 底长
h:高
"""
return a * h / 2
def triangle_area_s ( self, a, b, c) :
"""
求三角形面积 : 通过半周长求面积
a : 左边长
b: 有变长
c: 底边长
"""
h = ( a + b + c) / 2
return math. sqrt( h * ( h - a) * ( h - b) * ( h - c) )
def circle_area ( self, r) :
"""
求圆面积
r : 半径
"""
return math. pi * r ** 2
def ramdom_num ( self, n) :
"""
随机数
n : 截止数
"""
return random. randint( 1 , n)
def celsius_fahrenheit_temperature ( self, fahrenheit_temperature) :
"""
华氏温度转摄氏温度
fahrenheit_temperature :华氏温度
"""
return ( fahrenheit_temperature - 32 ) * 5 / 9
def fahrenheit_celsius_temperature ( self, celsius_temperature) :
"""
摄氏温度转华氏温度
celsius_temperature :摄氏温度
"""
return celsius_temperature * 9 / 5 + 32
def exchange_variable ( self) :
"""
交换两个变量的值
"""
a = 1
b = 2
print ( "交换前:a =" , a, "b =" , b)
a, b = b, a
print ( "交换后:a =" , a, "b =" , b)
def if_statement ( self) :
"""
if语句
"""
a = 1
b = 2
if a > b:
print ( "a > b" )
elif a < b:
print ( "a < b" )
def determain_str_is_num ( self, string) :
"""
判断字符串是否为数字
"""
if string. isdigit( ) :
return True
else :
return False
def determain_ood_even_num ( self, num) :
"""
判断数字是否为奇数、偶数
"""
if num % 2 == 0 :
return "偶数"
else :
return "奇数"
def determine_leap_year ( self, year) :
"""
判断是否为闰年
普通闰年:可以被4整除,但不能被100整除
实际闰年:必须被400整除
"""
if year % 4 == 0 and year % 100 != 0 or year % 400 == 0 :
return "闰年"
else :
return "平年"
def determine_max_value ( self, * keys) :
"""
求最大值
keys : 传入的数字
"""
return max ( keys)
def determine_prime ( self, num) :
"""
判断质数(素数),质数必须大于1,即1既不是质数也不是合数
num: 输入的数字
"""
if num <= 1 :
return "不是质数"
for i in range ( 2 , num) :
if num % i == 0 :
return "不是质数"
return "是质数"
def out_prime_num ( self, num) :
"""
输出所有小于或等于n的素数。
num : 指定范围的数字
"""
prime_lst = [ ]
if num < 2 :
return "不是素数"
for i in range ( 2 , num) :
flag = True
for j in range ( 2 , i) :
if i % j == 0 :
flag = False
break
else :
continue
if flag is False :
print ( i, "不是素数" )
else :
print ( i, "是素数" )
prime_lst. append( i)
return prime_lst
def out_prime_num_new ( self, num) :
"""
输出所有小于或等于n的素数。
num : 指定范围的数字
"""
prime_lst = [ ]
for i in range ( 2 , num) :
for j in range ( 2 , i) :
if i % j == 0 :
break
else :
prime_lst. append( i)
return prime_lst
def factorial ( self, n) :
"""
阶乘
"""
if n < 0 :
return "n 必须大于 0"
elif n == 0 :
return 1
else :
return n * self. factorial( n - 1 )
def multiplication_table ( self) :
"""
九九乘法表
"""
for i in range ( 1 , 10 ) :
for j in range ( 1 , i + 1 ) :
print ( '%d*%d=%d' % ( j, i, i * j) , end= '\t' )
print ( )
def fibonacci ( self, n) :
"""
斐波那契数列
"""
a, b = 0 , 1
while True :
yield a
a, b = b, a + b
if a > n:
break
def armstrong_number ( self, number) :
"""
检查一个数是否为阿姆斯特朗数。
参数:
number (int): 待检查的正整数。
返回值:
bool: 如果是阿姆斯特朗数,返回True;否则返回False。
"""
if number < 0 :
return "n 必须大于 0"
elif number == 0 :
return 0
else :
digits = [ int ( digit) for digit in str ( number) ]
num_digits = len ( digits)
sum_of_powers = sum ( digit ** num_digits for digit in digits)
return sum_of_powers == number
def decimal_conversion ( self, n) :
"""
将十进制数转换为二进制数,八进制、16进制
参数:
n(int):转换的数字
返回值:
转换后的值
"""
return bin ( n) + " " + oct ( n) + " " + hex ( n)
def asxii_character ( self, n) :
"""
将十进制数转换为ASCII字符
参数:
n(int):转换的数字
返回值:
转换后的值
"""
if str ( n) . isdigit( ) and 0 <= n <= 255 :
return chr ( n)
if str ( n) . isalpha( ) :
return ord ( n)
def maximum_common_divisor ( self, n, m) :
"""
最大公约数:欧几里得算法(辗转相除法):(1,最小的数)
参数:
n,m(int):数字
"""
if n <= 0 or m <= 0 :
return "n,m 必须大于 0"
else :
while m != 0 :
n, m = m, n % m
return n
def minimum_common_multiple ( self, n, m) :
"""
最小公倍数:
计算最小公倍数常常与最大公约数(GCD)结合使用,因为两者之间存在密切关系;
对于任意两个非零整数 a 和 b,它们的最小公倍数 LCM(a, b) 可以通过它们的最大公约数 GCD(a, b) 以及它们的乘积来确定,遵循以下公式:
[ LCM(a, b) = \frac{|a \times b|}{GCD(a, b)} ]
其中 |a \times b| 表示 a 和 b 乘积的绝对值。这个公式表明,一旦知道了两个数的最大公约数,就可以快速计算它们的最小公倍数,而无需列举所有共同倍数。
"""
return abs ( n * m) // math. gcd( n, m)
def simple_calculator ( self, num1, num2, operator) :
"""
简单的计算器
"""
while True :
try :
if operator == '+' :
result = num1 + num2
elif operator == '-' :
result = num1 - num2
elif operator == '*' :
result = num1 * num2
elif operator == '/' :
result = num1 / num2
else :
print ( "输入有误,请重新输入" )
continue
return result
except :
print ( "输入有误,请重新输入" )
continue
def generate_calendar ( self, year, month) :
"""
生成日历
"""
print ( calendar. month( year, month) )
def recursive_fibonacci ( self, n) :
"""
递归求斐波那契数列
斐波那契数列定义如下:
F(0) = 0
F(1) = 1
F(n) = F(n-1) + F(n-2) (n >= 2)
"""
if n < 0 :
return "n 必须大于 0"
elif n == 0 :
return 0
elif n == 1 :
return 1
else :
return self. recursive_fibonacci( n - 1 ) + self. recursive_fibonacci( n - 2 )
def file_io ( self) :
"""
文件读写
"""
with open ( 'test.txt' , 'wt' ) as f:
f. write( 'Hello, World!' )
with open ( 'test.txt' , 'rt' ) as f:
content = f. read( )
print ( content)
def sty_operation ( self) :
"""
字符串操作
"""
print ( "测试实例一" )
str = "runoob.com"
print ( str . isalnum( ) )
print ( str . isalpha( ) )
print ( str . isdigit( ) )
print ( str . islower( ) )
print ( str . isupper( ) )
print ( str . istitle( ) )
print ( str . isspace( ) )
print ( "------------------------" )
print ( "测试实例二" )
str = "runoob"
print ( str . isalnum( ) )
print ( str . isalpha( ) )
print ( str . isdigit( ) )
print ( str . islower( ) )
print ( str . isupper( ) )
print ( str . istitle( ) )
print ( str . isspace( ) )
def str_upper_lower ( self) :
"""
字符串大小写转换
"""
str = "www.runoob.com"
print ( str . upper( ) )
print ( str . lower( ) )
print ( str . swapcase( ) )
print ( str . title( ) )
print ( str . capitalize( ) )
def calculate_month_days ( self, year, month) :
"""
计算月份天数
"""
if month in [ 1 , 3 , 5 , 7 , 8 , 10 , 12 ] :
return 31
elif month in [ 4 , 6 , 9 , 11 ] :
return 30
elif month == 2 :
if ( year % 4 == 0 and year % 100 != 0 ) or year % 400 == 0 :
return 29
else :
return 28
else :
return "输入的月份有误"
def get_yestarday_date ( self) :
"""
获取昨天的日期
"""
yesterday = datetime. date. today( ) - datetime. timedelta( days= 1 )
return yesterday
def list_operation ( self) :
"""
列表操作
"""
list1 = [ 1 , 2 , 3 , 4 , 5 ]
list2 = [ 6 , 7 , 8 , 9 , 10 ]
list3 = list1 + list2
print ( list3)
list3. append( 11 )
print ( list3)
list3. insert( 0 , 0 )
print ( list3)
list3. remove( 0 )
print ( list3)
list3. pop( )
print ( list3)
list3. reverse( )
print ( list3)
list3. sort( )
def josephus_survivor ( self, n: int , m: int , start_person: int = 0 ) - > int :
"""
计算约瑟夫生者死者游戏中存活者的编号。
游戏规则:
假设有 n 个人站成一个圈。
从某个指定的人开始(编号为1或0),按照顺时针或逆时针方向从1开始报数。
每当报到某个特定的数(如 m),报该数的人被淘汰(离开圈子)。
然后从被淘汰人的下一个顺(逆)时针的人继续报数,依此类推。
游戏继续进行,直到只剩下最后一个人,这个人即为“生者”。
参数:
n (int): 总人数。
m (int): 报数间隔(报到m的人被淘汰)。
start_person (int): 开始报数的人员编号,默认为0(从第一个人开始)。
返回值:
int: 存活者的编号。
"""
def josephus_step ( people: list [ int ] , start_person) - > int :
if len ( people) == 1 :
return people[ 0 ]
index = ( start_person + m - 1 ) % len ( people)
eliminated = people. pop( index)
return josephus_step( people, index)
people = list ( range ( n) )
return josephus_step( people, start_person)
def people_divide_fish ( self) :
"""
五人分鱼,求至少捕多少鱼
"""
fish = 1
while True :
total, enough = fish, True
for _ in range ( 5 ) :
if ( total - 1 ) % 5 == 0 :
total = ( total - 1 ) // 5 * 4
else :
enough = False
break
if enough:
print ( f'总共有 { fish} 条鱼' )
break
fish += 1
return fish
def five_people_divide_fish ( self) :
"""
五人分鱼,求至少捕多少鱼
"""
e_fish_count = 1
for _ in range ( 4 ) :
e_fish_count = ( e_fish_count + 1 ) * 4 - 1
return e_fish_count
def impl_stopwatch ( self) :
"""
实现一个计时器
"""
import time
start_time = time. time( )
time. sleep( 5 )
end_time = time. time( )
print ( "程序运行时间:" , end_time - start_time, "秒" )
def cube_sum ( self, * keys) :
"""
立方和
"""
return sum ( key ** 3 for key in keys)
def sum_array ( self, arr) :
"""
求数组的和
"""
return sum ( arr)
def array_flip ( self, arr, num_to_move) :
"""
将数组中指定个数的元素翻转并移动到数组的尾部。
参数:
arr (list): 输入的整型数组。
num_to_move (int): 指定要翻转并移动的元素个数。
返回:
list: 处理后的数组。
"""
if num_to_move <= 0 or num_to_move > len ( arr) :
raise ValueError( "num_to_move 必须是正整数且不超过数组长度" )
reversed_subarray = arr[ : num_to_move] [ : : - 1 ]
arr = arr[ num_to_move: ]
arr. extend( reversed_subarray)
return arr
def array_swap_last_two_elements ( self, arr) :
"""
将列表中的头尾两个元素对调。//将列表中的指定位置的两个元素对调
参数:
arr (list): 输入的列表。
返回:
list: 头尾元素对调后的列表。
"""
if len ( arr) < 2 :
return arr
arr[ 0 ] , arr[ - 1 ] = arr[ - 1 ] , arr[ 0 ]
return arr
def reverse_array ( self, arr) :
"""
反转列表//判断元素是否在列表中存在
"""
print ( 4 in arr)
return arr[ : : - 1 ]
def remove_duplicates ( self, arr) :
"""
移除列表中的重复元素
"""
return list ( set ( arr) )
def copy_list ( self, arr) :
"""
copy 列表
"""
return arr. copy( )
def caculate_element_time ( self, arr, n) :
"""
计算元素出现的次数
"""
def caculate_element_sum ( self, arr) :
"""
计算列表中每个元素的和
"""
return sum ( arr)
def caculate_element_multiplier ( self, arr) :
"""
计算列表中每个元素的乘积、最大、最小
"""
print ( "最小元素" , min ( arr) )
print ( "最大元素" , max ( arr) )
return reduce ( lambda x, y: x * y, arr)
def str_operation ( self) :
"""
字符串操作:
移除字符串中的指定位置字符
判断字符串是否存在子字符串
判断字符串长度
"""
print ( "字符串长度:" , len ( "Hello, World!" ) )
print ( "字符串反转:" , "Hello, World!" [ : : - 1 ] )
print ( "字符串替换:" , "Hello, World!" . replace( "World" , "Python" ) )
print ( "字符串分割:" , "Hello, World!" . split( "," ) )
print ( "字符串连接:" , "Hello, " + "World!" )
print ( "字符串查找:" , "Hello, World!" . find( "World" ) )
print ( "字符串切片:" , "Hello, World!" [ 6 : 12 ] )
print ( "字符串大写:" , "Hello, World!" . upper( ) )
print ( "字符串小写:" , "Hello, World!" . lower( ) )
print ( "字符串首字母大写:" , "Hello, World!" . capitalize( ) )
print ( "移除字符串中的指定位置字符" , "Hello, World!" [ 0 : - 1 ] )
print ( "判断字符串是否存在子字符串" , "hello" in "Hello, World!" )
def re_str ( self, string) :
"""
正则表达式
"""
"""
https? : http 或者 https
(?:[-\w.]|(?:%[\da-fA-F]{2}))+
?:[-\w.] : 分组捕获, 匹配字母、数字或下划线
?:%[\da-fA-F]{2} :
"""
url = re. findall( 'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+' , string)
return url
def str_code ( self, string) :
"""
字符串作为代码执行
"""
exec ( string)
def oper_dict ( self) :
"""
字典操作
"""
d = { 'name' : 'John' , 'age' : 25 , 'city' : 'New York' }
m = { 'addr' : 'xian' , 'temp' : "35℃" }
print ( "字典长度:" , len ( d) )
print ( "字典键值对:" , d. items( ) )
print ( "字典键:" , d. keys( ) )
print ( "字典值:" , d. values( ) )
print ( "字典键是否存在:" , 'name' in d)
print ( "字典键不存在:" , 'country' not in d)
print ( "字典键值对:" , d. get( 'name' ) )
sorted ( d. items( ) )
print ( "字典键值对排序:" , d)
d. update( m)
print ( "合并字典:" , d)
print ( "删除字典键值对:" , d. pop( 'name' ) )
def date_oper ( self) :
"""
日期操作
"""
print ( "当前日期:" , datetime. datetime. now( ) )
print ( "当前日期:" , datetime. datetime. now( ) . strftime( "%Y-%m-%d %H:%M:%S" ) )
print ( "当前日期:" , datetime. datetime. now( ) . strftime( "%Y-%m-%d" ) )
print ( "时间戳:" , time. mktime( datetime. datetime. now( ) . timetuple( ) ) )
print ( "几天前的时间:" , datetime. datetime. now( ) - datetime. timedelta( days= 3 ) )
print ( "时间戳转换为指定格式日期:" ,
datetime. datetime. fromtimestamp( time. mktime( datetime. datetime. now( ) . timetuple( ) ) ) )
def binary_search ( self, arr, target) :
"""
二分查找:
二分查找的时间复杂度为 O(log n),其中 n 是数组的长度。由于每次迭代都将搜索区间缩小一半,因此对于大规模数据,二分查找比线性查找(O(n))更为高效。请注意,二分查找的前提是数据已经排序。如果数据未排序,需要先进行排序操作,这将增加额外的时间复杂度。
"""
left = 0
right = len ( arr) - 1
while left <= right:
mid = ( left + right) // 2
if arr[ mid] == target:
return mid
elif arr[ mid] < target:
left = mid + 1
else :
right = mid - 1
print ( "没有找到目标值" )
return - 1
def linear_search ( self, arr, target) :
"""
线性查找
"""
for i in range ( len ( arr) ) :
if arr[ i] == target:
return i
return - 1
def insertion_sort ( self, arr) :
"""
插入排序:
插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
"""
for i in range ( 1 , len ( arr) ) :
key = arr[ i]
j = i - 1
while j >= 0 and arr[ j] > key:
arr[ j + 1 ] = arr[ j]
j -= 1
arr[ j + 1 ] = key
return arr
def quick_sort ( self, arr) :
"""
快速排序:
快速排序(英语:Quicksort)是一种排序算法,由东尼·霍尔所创建。在平均状况下,排序n个项目要 Ο(n log n)次比较。在最坏状况下则需要 Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序(Quick Sort)是一种高效的排序算法,基于分治(Divide and Conquer)策略。其主要思想是选择一个基准元素(pivot),将数组分为两部分:一部分包含所有比基准小的元素,另一部分包含所有比基准大的元素。然后对这两部分递归地应用快速排序,最终得到有序数组。以下是快速排序的基本步骤及 Python 代码实现:
快速排序算法描述:
选择基准:选择一个基准元素(通常为数组的中间元素或随机元素)。
分区(Partition):重新排列数组,使得基准元素左边的所有元素都不大于它,右边的所有元素都不小于它。在此过程中,记录基准元素最终所在的位置(即正确排序后的位置)。
递归排序:对基准元素左边和右边的两个子数组分别进行快速排序。
"""
if len ( arr) <= 1 :
return arr
pivot = arr[ len ( arr) // 2 ]
less = [ x for x in arr if x < pivot]
greater = [ x for x in arr if x > pivot]
return self. quick_sort( less) + [ pivot] + self. quick_sort( greater)
def selection_sort ( self, arr) :
"""
选择排序:
选择排序(英语:Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部元素排序完毕。
"""
for i in range ( len ( arr) ) :
min_index = i
for j in range ( i + 1 , len ( arr) ) :
if arr[ j] < arr[ min_index] :
min_index = j
arr[ i] , arr[ min_index] = arr[ min_index] , arr[ i]
return arr
def bubble_sort ( self, arr) :
"""
冒泡排序:
冒泡排序(英语:Bubble sort)是一种简单直观的排序算法。它的工作原理是通过重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
"""
for i in range ( len ( arr) ) :
for j in range ( len ( arr) - i - 1 ) :
if arr[ j] > arr[ j + 1 ] :
arr[ j] , arr[ j + 1 ] = arr[ j + 1 ] , arr[ j]
return arr
def merge_sort ( self, arr) :
"""
归并排序:
归并排序(英语:Merge sort)是采用分治法(Divide and conquer)的一个排序算法。该算法是采用分治法来对数组进行排序。将数组分为左右两部分,递归排序,然后合并两个排序的子数组。
"""
if len ( arr) <= 1 :
return arr
mid = len ( arr) // 2
left = self. merge_sort( arr[ : mid] )
right = self. merge_sort( arr[ mid: ] )
return self. merge( left, right)
def merge ( self, left, right) :
merged = [ ]
i = j = 0
while i < len ( left) and j < len ( right) :
if left[ i] < right[ j] :
merged. append( left[ i] )
i += 1
else :
merged. append( right[ j] )
j += 1
merged. extend( left[ i: ] )
merged. extend( right[ j: ] )
return merged
def heapify ( self, arr, n, i) :
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and arr[ i] < arr[ l] :
largest = l
if r < n and arr[ largest] < arr[ r] :
largest = r
if largest != i:
arr[ i] , arr[ largest] = arr[ largest] , arr[ i]
self. heapify( arr, n, largest)
def heap_sort ( self, arr) :
"""
堆排序:
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。
"""
n = len ( arr)
for i in range ( n, - 1 , - 1 ) :
self. heapify( arr, n, i)
for i in range ( n - 1 , 0 , - 1 ) :
arr[ i] , arr[ 0 ] = arr[ 0 ] , arr[ i]
self. heapify( arr, i, 0 )
return arr
def counting_sort ( self, arr, exp) :
"""
辅助函数:计数排序(Counting Sort),用于对某一位进行排序。
arr: 待排序数组
exp: 当前处理的位数(指数)
"""
n = len ( arr)
output = [ 0 ] * n
count = [ 0 ] * 10
for i in range ( n) :
index = arr[ i] // exp % 10
count[ index] += 1
for i in range ( 1 , 10 ) :
count[ i] += count[ i - 1 ]
for i in range ( n - 1 , - 1 , - 1 ) :
index = arr[ i] // exp % 10
count[ index] -= 1
output[ count[ index] ] = arr[ i]
return output
def radix_sort ( self, arr) :
"""
计数排序:
计数排序(Counting sort)是一种非比较型整数排序算法,其思路是:遍历输入数据,将输入数据的每个元素出现的次数计算出来,最后将计数数组中的值依次累加,得出每个元素在排序后的位置。
"""
max_val = max ( arr)
exp = 1
while max_val // exp > 0 :
arr = self. counting_sort( arr, exp)
exp *= 10
return arr
def shell_sort ( self, arr) :
"""
希尔排序:
希尔排序(Shell sort)是插入排序的一种。希尔排序是把记录按下标的一定增量分组,对每组使用插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
"""
n = len ( arr)
gap = n // 2
while gap > 0 :
for i in range ( gap, n) :
current = arr[ i]
j = i
while j >= gap and arr[ j - gap] > current:
arr[ j] = arr[ j - gap]
j -= gap
arr[ j] = current
gap //= 2
return arr
def topological_sort ( self, graph) :
"""
拓扑排序
graph: 以邻接表形式表示的有向图,形如 {节点: [邻接节点]}
"""
sorted_nodes = [ ]
in_degree = { node: 0 for node in graph}
for node, neighbors in graph. items( ) :
for neighbor in neighbors:
in_degree[ neighbor] += 1
queue = deque( [ node for node, degree in in_degree. items( ) if degree == 0 ] )
while queue:
node = queue. popleft( )
sorted_nodes. append( node)
for neighbor in graph[ node] :
in_degree[ neighbor] -= 1
if in_degree[ neighbor] == 0 :
queue. append( neighbor)
return sorted_nodes if len ( sorted_nodes) == len ( graph) else None
if __name__ == '__main__' :
x = Example( )
print ( x. hello_wolrd( ) )
print ( x. sum_num( 1 , 2 , 3 , 4 , 5 ) )
print ( x. square_root( 9 ) )
x. quadratic_equation( 'x^2 + 3x + 2 = 0' )
print ( "已知 底边长和高,求三角形的的面积:" , x. triangle_area( 3 , 4 ) )
print ( "已知 三边长,求三角形的的面积:" , x. triangle_area_s( 3 , 4 , 5 ) )
print ( f"已知半径 { 3 } ,求圆的面积: { x. circle_area( 3 ) } " )
print ( "随机数:" , x. ramdom_num( 10 ) )
print ( "华氏温度转摄氏温度:" , x. celsius_fahrenheit_temperature( 100 ) )
print ( "摄氏温度转华氏温度:" , x. fahrenheit_celsius_temperature( 38 ) )
x. exchange_variable( )
x. if_statement( )
print ( "是否为数字:" , x. determain_str_is_num( '123' ) )
print ( "是否为数字:" , x. determain_str_is_num( 'aaa' ) )
print ( "是否为奇数:" , x. determain_ood_even_num( 1 ) )
print ( "判断是否为闰年:" , x. determine_leap_year( 2024 ) )
print ( "最大值是:" , x. determine_max_value( 1 , 2 , 3 , 7 , 3 , 7 , 34 , 8 , 34 , 123 , 4356 , 223344 , 11 , 67842 ) )
print ( "16是否为质数:" , x. determine_prime( 16 ) )
print ( "其中素数是:" , x. out_prime_num( 17 ) )
print ( "其中素数是:" , x. out_prime_num_new( 17 ) )
print ( "阶乘:" , x. factorial( 5 ) )
x. multiplication_table( )
print ( "*" * 50 )
for i in x. fibonacci( 100 ) :
print ( i, end= ' ' )
print ( "*" * 50 )
print ( "阿姆斯特朗数" , x. armstrong_number( 153 ) )
for i in range ( 1 , 10000 ) :
if x. armstrong_number( i) :
print ( i, end= " " )
print ( "*" * 50 )
print ( i for i in range ( 1 , 10000 ) if x. armstrong_number( i) )
print ( "进制转换:" , x. decimal_conversion( 10 ) )
print ( "ASCII转字符:" , x. asxii_character( 'A' ) )
print ( "最大公约数:" , x. maximum_common_divisor( 8 , 12 ) , math. gcd( 8 , 12 ) )
print ( "最小公倍数:" , x. minimum_common_multiple( 8 , 12 ) , math. lcm( 8 , 12 ) )
print ( "计算器:" , x. simple_calculator( 4 , 5 , '+' ) )
print ( "生成日历:" , x. generate_calendar( 2023 , 5 ) )
for i in range ( 10 ) :
print ( x. recursive_fibonacci( i) )
print ( "文件读写:" , x. file_io( ) )
print ( "字符串操作:" , x. sty_operation( ) )
print ( "字符串大小写转换:" , x. str_upper_lower( ) )
print ( "计算月份天数:" , x. calculate_month_days( 2023 , 5 ) , calendar. monthrange( 2023 , 5 ) )
print ( "获取昨天的日期:" , x. get_yestarday_date( ) )
print ( "列表操作:" , x. list_operation( ) )
print ( "计算约瑟夫生者死者游戏中存活者的编号:" , x. josephus_survivor( 50 , 6 ) )
print ( "五人分鱼:" , x. people_divide_fish( ) )
print ( "五人分鱼:" , x. five_people_divide_fish( ) )
x. impl_stopwatch( )
print ( "立方和:" , x. cube_sum( 1 , 2 , 3 , 4 , 5 ) )
print ( "求数组的和:" , x. sum_array( [ 1 , 2 , 3 , 4 , 5 ] ) )
print ( "将数组中指定个数的元素翻转并移动到数组的尾部:" , x. array_flip( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] , 2 ) )
print ( "将列表中的头尾两个元素对调:" , x. array_swap_last_two_elements( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "反转列表:" , x. reverse_array( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "清空列表:" , [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] . clear( ) )
print ( "移除列表中的重复元素:" , x. remove_duplicates( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "copy 列表:" , x. copy_list( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "计算元素出现的次数:" , x. caculate_element_time( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] , 1 ) )
print ( "计算列表中每个元素的和:" , x. caculate_element_sum( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "计算列表中每个元素的乘积:" , x. caculate_element_multiplier( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "字符串操作:" , x. str_operation( ) )
print ( "正则表达式:" ,
x. re_str( "Runoob 的网页地址为:https://www.runoob.com,Google 的网页地址为:https://www.google.com" ) )
print ( "字符串作为代码执行:" , x. str_code( "print('Hello, World!')" ) )
print ( "字典操作:" , x. oper_dict( ) )
print ( "日期操作:" , x. date_oper( ) )
print ( "二分查找" , x. binary_search( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] , 5 ) )
sorted_array = [ 1 , 12 , 3 , 5 , 8 , 10 , 13 , 15 , 17 ]
target = 12
sorted_array. sort( )
print ( "二分查找,未排序数组" , x. binary_search( sorted_array, target) )
print ( "线性查找" , x. linear_search( [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] , 5 ) )
print ( "插入排序" , x. insertion_sort( [ 5 , 6 , 7 , 3 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "快速排序" , x. quick_sort( [ 5 , 6 , 7 , 3 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "选择排序" , x. selection_sort( [ 5 , 6 , 7 , 3 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "冒泡排序" , x. bubble_sort( [ 8 , 6 , 4 , 3 , 4 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "归并排序" , x. merge_sort( [ 8 , 6 , 4 , 3 , 4 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "堆排序" , x. heap_sort( [ 8 , 6 , 4 , 3 , 4 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "计数排序" , x. radix_sort( [ 8 , 6 , 4 , 3 , 4 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
print ( "希尔排序" , x. shell_sort( [ 8 , 6 , 4 , 3 , 4 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] ) )
graph = {
'A' : [ 'B' , 'C' ] ,
'B' : [ 'D' , 'E' ] ,
'C' : [ 'F' ] ,
'D' : [ ] ,
'E' : [ 'F' ] ,
'F' : [ ]
}
print ( "拓扑排序" , x. topological_sort( graph) )









![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.3](https://img-blog.csdnimg.cn/direct/58f6061acffc4b5fb8ceca3f41b38835.png)